Instrukcja korzystania z jSQL Injection, wielofunkcyjnego narzędzia do wyszukiwania i wykorzystywania zastrzyków SQL w Kali Linux. O dorks lub wszystkich miłośnikach prywatnych dorks Organizacje inurl recenzje php
Uruchom pobrany plik poprzez podwójne kliknięcie (musisz posiadać maszynę wirtualną).
3. Anonimowość podczas sprawdzania witryny pod kątem wstrzyknięcia SQL
Konfigurowanie Tora i Privoxy w Kali Linux
[Sekcja w przygotowaniu]
Konfigurowanie Tora i Privoxy w systemie Windows
[Sekcja w przygotowaniu]
Ustawienia proxy we wstrzykiwaniu jSQL
[Sekcja w przygotowaniu]
4. Sprawdzenie witryny pod kątem iniekcji SQL za pomocą jSQL Injection
Praca z programem jest niezwykle prosta. Wystarczy wpisać adres strony internetowej i nacisnąć ENTER.
Poniższy zrzut ekranu pokazuje, że witryna jest podatna na trzy rodzaje zastrzyków SQL (informacja o nich jest wskazana w prawym dolnym rogu). Klikając na nazwy zastrzyków możesz zmienić zastosowaną metodę:

Wyświetlono nam już także istniejące bazy danych.
Możesz wyświetlić zawartość każdej tabeli:

Zazwyczaj najciekawszą rzeczą w tabelach są poświadczenia administratora.
Jeśli będziesz mieć szczęście i odnajdziesz dane administratora, to jest za wcześnie na radość. Musisz jeszcze znaleźć panel administracyjny, w którym możesz wprowadzić te dane.
5. Wyszukaj panele administracyjne za pomocą jSQL Injection
W tym celu przejdź do kolejnej zakładki. Tutaj wita nas lista możliwych adresów. Możesz wybrać jedną lub więcej stron do sprawdzenia:

Wygoda polega na tym, że nie trzeba korzystać z innych programów.
Niestety, nie ma zbyt wielu nieostrożnych programistów, którzy przechowują hasła w postaci zwykłego tekstu. Dość często w wierszu hasła widzimy coś takiego
8743b52063cd84097a65d1633f5c74f5
To jest skrót. Możesz go odszyfrować za pomocą brutalnej siły. I... jSQL Injection ma wbudowaną brute-forcer.
6. Mieszanie brutalnej siły przy użyciu wtrysku jSQL
Niewątpliwą wygodą jest to, że nie trzeba szukać innych programów. Istnieje wsparcie dla wielu najpopularniejszych skrótów.
To nie jest najlepsza opcja. Aby zostać guru w dekodowaniu skrótów, zaleca się książkę „” w języku rosyjskim.
Ale oczywiście, gdy nie ma pod ręką innego programu lub nie ma czasu na naukę, bardzo przydatny będzie jSQL Injection z wbudowaną funkcją brute force.

Istnieją ustawienia: możesz ustawić, które znaki mają być zawarte w haśle, zakres długości hasła.
7. Operacje na plikach po wykryciu zastrzyków SQL
Oprócz operacji na bazach danych - ich odczytywania i modyfikowania, w przypadku wykrycia zastrzyków SQL, można wykonać następujące operacje na plikach:
- czytanie plików na serwerze
- wgranie nowych plików na serwer
- przesyłanie powłok na serwer
A wszystko to jest zaimplementowane w jSQL Injection!
Istnieją ograniczenia - serwer SQL musi mieć uprawnienia do plików. Inteligentni administratorzy systemu wyłączyli je i nie będą mogli uzyskać dostępu do systemu plików.
Obecność uprawnień do plików można dość łatwo sprawdzić. Przejdź do jednej z zakładek (odczyt plików, utworzenie powłoki, wgranie nowego pliku) i spróbuj wykonać jedną z określonych operacji.
Kolejna bardzo ważna uwaga - musimy znać dokładną bezwzględną ścieżkę do pliku, z którym będziemy pracować - w przeciwnym razie nic nie będzie działać.
Spójrz na poniższy zrzut ekranu:
 Na każdą próbę operacji na pliku otrzymujemy następującą odpowiedź: Brak uprawnień FILE(brak uprawnień do plików). I nic tu nie da się zrobić.
Na każdą próbę operacji na pliku otrzymujemy następującą odpowiedź: Brak uprawnień FILE(brak uprawnień do plików). I nic tu nie da się zrobić.
Jeśli zamiast tego pojawi się inny błąd:
Problem z zapisem do [nazwa_katalogu]
Oznacza to, że niepoprawnie podałeś ścieżkę bezwzględną, w której chcesz zapisać plik.
Aby odgadnąć ścieżkę bezwzględną, musisz przynajmniej znać system operacyjny, na którym działa serwer. Aby to zrobić, przejdź do zakładki Sieć.
Taki zapis (linia Win64) daje nam podstawy przypuszczać, że mamy do czynienia z systemem operacyjnym Windows:
Keep-Alive: limit czasu=5, max=99 Serwer: Apache/2.4.17 (Win64) PHP/7.0.0RC6 Połączenie: Metoda Keep-Alive: HTTP/1.1 200 OK Długość zawartości: 353 Data: piątek, 11 grudnia 2015 11:48:31 GMT X-Powered-By: PHP/7.0.0RC6 Typ zawartości: tekst/html; zestaw znaków=UTF-8
Tutaj mamy trochę Uniksa (*BSD, Linux):
Kodowanie transferu: fragmentaryczne Data: piątek, 11 grudnia 2015 r. 11:57:02 GMT Metoda: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 Połączenie: keep-alive Typ zawartości: tekst/html X- Obsługiwane przez: PHP/5.3.29 Serwer: Apache/2.2.31 (Unix)
A tutaj mamy CentOS:
Metoda: HTTP/1.1 200 OK Wygasa: czwartek, 19 listopada 1981 08:52:00 GMT Set-Cookie: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; ścieżka=/ Połączenie: keep-alive X-Cache-Lookup: MISS z t1.hoster.ru:6666 Serwer: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.4.37 X-Cache: MISS z t1.hoster.ru Kontrola pamięci podręcznej: brak przechowywania, brak pamięci podręcznej, konieczna ponowna weryfikacja, sprawdzanie końcowe = 0, sprawdzanie wstępne = 0 Pragma: brak pamięci podręcznej Data: piątek, 11 grudnia 2015 12:08:54 GMT Kodowanie transferu: fragmentaryczne Typ zawartości: tekst/html; zestaw znaków=WINDOWS-1251
W systemie Windows typowym folderem witryn jest C:\Serwer\dane\htdocs\. Ale tak naprawdę, jeśli ktoś „pomyślał” o stworzeniu serwera w systemie Windows, to najprawdopodobniej ta osoba nie słyszała nic o przywilejach. Dlatego powinieneś rozpocząć próbę bezpośrednio z katalogu C:/Windows/:
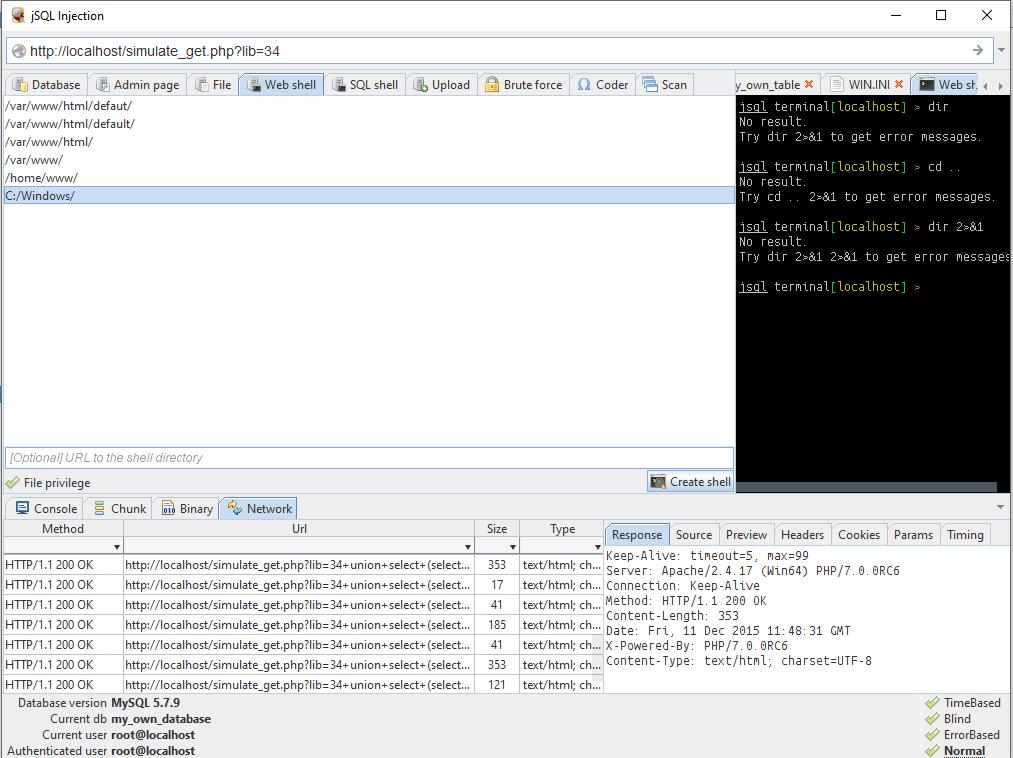
Jak widać, wszystko poszło dobrze za pierwszym razem.
Ale same powłoki jSQL Injection budzą moje wątpliwości. Jeśli masz uprawnienia do plików, możesz łatwo przesłać coś za pomocą interfejsu internetowego.
8. Zbiorcze sprawdzanie witryn pod kątem zastrzyków SQL
I nawet ta funkcja jest dostępna w jSQL Injection. Wszystko jest niezwykle proste - pobierz listę witryn (możesz zaimportować z pliku), wybierz te, które chcesz sprawdzić i kliknij odpowiedni przycisk, aby rozpocząć operację.

Wniosek z wtrysku jSQL
jSQL Injection to dobre, potężne narzędzie do wyszukiwania, a następnie wykorzystania zastrzyków SQL znalezionych na stronach internetowych. Jego niewątpliwe zalety: łatwość obsługi, wbudowane funkcje z tym związane. jSQL Injection może być najlepszym przyjacielem początkującego przy analizie stron internetowych.
Wśród niedociągnięć zwróciłbym uwagę na brak możliwości edycji baz danych (przynajmniej ja nie znalazłem takiej funkcjonalności). Podobnie jak w przypadku wszystkich narzędzi GUI, jedną z wad tego programu można przypisać niemożności użycia go w skryptach. Niemniej jednak w tym programie możliwa jest również pewna automatyzacja - dzięki wbudowanej funkcji masowego sprawdzania witryny.
ustalona próbka i certyfikat. Specjalna zniżka na dowolne wydziały i kursy!
Zdobycie prywatnych danych nie zawsze oznacza włamanie – czasami są one publikowane publicznie. Znajomość ustawień Google i odrobina pomysłowości pozwolą Ci znaleźć wiele ciekawych rzeczy – od numerów kart kredytowych po dokumenty FBI.
OSTRZEŻENIE
Wszystkie informacje podane są wyłącznie w celach informacyjnych. Ani redakcja, ani autor nie ponoszą odpowiedzialności za ewentualne szkody wyrządzone przez materiały zawarte w tym artykule.Dziś wszystko jest podłączone do Internetu i nie ma potrzeby ograniczania dostępu. Dlatego wiele prywatnych danych staje się ofiarą wyszukiwarek. Roboty-pająki nie ograniczają się już do stron internetowych, ale indeksują wszystkie treści dostępne w Internecie i na bieżąco dodają do swoich baz danych informacje niepubliczne. Odkrycie tych tajemnic jest łatwe - wystarczy wiedzieć, jak o nie zapytać.
Szukam plików
W zdolnych rękach Google szybko znajdzie wszystko, czego nie ma w Internecie, na przykład dane osobowe i pliki do użytku służbowego. Często są ukryte jak klucz pod dywanikiem: nie ma tak naprawdę żadnych ograniczeń dostępu, dane po prostu leżą na odwrocie strony, dokąd nie prowadzą żadne linki. Standardowy interfejs sieciowy Google udostępnia jedynie podstawowe ustawienia wyszukiwania zaawansowanego, ale i one będą wystarczające.
Możesz ograniczyć wyszukiwanie w Google do określonego typu pliku, używając dwóch operatorów: filetype i ext . Pierwsza określa format, który wyszukiwarka ustaliła na podstawie tytułu pliku, druga określa rozszerzenie pliku, niezależnie od jego wewnętrznej zawartości. Podczas wyszukiwania w obu przypadkach wystarczy podać rozszerzenie. Początkowo operator ext był wygodny w użyciu w przypadkach, gdy plik nie miał określonej charakterystyki formatu (na przykład w celu wyszukiwania plików konfiguracyjnych ini i cfg, które mogły zawierać cokolwiek). Teraz algorytmy Google uległy zmianie i nie ma widocznej różnicy pomiędzy operatorami – w większości przypadków wyniki są takie same.

Filtrowanie wyników
Domyślnie Google wyszukuje słowa i ogólnie wszelkie wprowadzone znaki we wszystkich plikach na zaindeksowanych stronach. Możesz ograniczyć obszar wyszukiwania według domeny najwyższego poziomu, konkretnej witryny lub lokalizacji sekwencji wyszukiwania w samych plikach. W przypadku dwóch pierwszych opcji użyj operatora witryny, a następnie nazwy domeny lub wybranej witryny. W trzecim przypadku cały zestaw operatorów pozwala na wyszukiwanie informacji w polach usług i metadanych. Przykładowo allinurl znajdzie podany w treści samych linków, allinanchor - w tekście wyposażonym w tag , allintitle – w tytułach stron, allintext – w treści stron.
Dla każdego operatora dostępna jest uproszczona wersja z krótszą nazwą (bez przedrostka all). Różnica jest taka, że allinurl znajdzie linki do wszystkich słów, a inurl tylko do pierwszego z nich. Drugie i kolejne słowa zapytania mogą pojawić się w dowolnym miejscu na stronach internetowych. Operator inurl różni się także od innego operatora o podobnym znaczeniu – site. Pierwsza pozwala także na znalezienie dowolnego ciągu znaków w łączu do przeszukiwanego dokumentu (np. /cgi-bin/), co jest powszechnie stosowane w celu znalezienia komponentów ze znanymi lukami w zabezpieczeniach.
Spróbujmy tego w praktyce. Bierzemy filtr allintext i sprawiamy, że żądanie generuje listę numerów i kodów weryfikacyjnych kart kredytowych, które wygasną dopiero za dwa lata (lub gdy ich właściciele znudzą się karmieniem wszystkich).
Allintext: data ważności numeru karty /2017 cvv 
Kiedy czytasz w wiadomościach, że młody haker „włamał się na serwery” Pentagonu lub NASA, kradnąc tajne informacje, w większości przypadków mamy na myśli właśnie taką podstawową technikę korzystania z Google. Załóżmy, że interesuje nas lista pracowników NASA i ich dane kontaktowe. Z pewnością taka lista jest dostępna w formie elektronicznej. Dla wygody lub z powodu przeoczenia może on również znajdować się na stronie internetowej samej organizacji. Logiczne jest, że w tym przypadku nie będzie żadnych linków do niego, ponieważ jest on przeznaczony do użytku wewnętrznego. Jakie słowa mogą znajdować się w takim pliku? Co najmniej - pole „adres”. Testowanie wszystkich tych założeń jest łatwe.

Inurl:nasa.gov typ pliku:xlsx „adres”

Stosujemy biurokrację
Takie znaleziska są miłym akcentem. Naprawdę solidny chwyt zapewnia bardziej szczegółowa wiedza o operatorach Google dla webmasterów, samej sieci i osobliwościach struktury tego, czego szukasz. Znając szczegóły, możesz łatwo przefiltrować wyniki i udoskonalić właściwości niezbędnych plików, aby w pozostałej części uzyskać naprawdę wartościowe dane. Zabawne, że tu z pomocą przychodzi biurokracja. Tworzy standardowe formuły, wygodne do wyszukiwania tajnych informacji, które przypadkowo wyciekły do Internetu.
Na przykład pieczęć z oświadczeniem o dystrybucji, wymagana przez Departament Obrony USA, oznacza ustandaryzowane ograniczenia dotyczące dystrybucji dokumentu. Litera A oznacza publikacje publiczne, w których nie ma nic tajnego; B – przeznaczony wyłącznie do użytku wewnętrznego, C – ściśle poufny i tak dalej, aż do F. Litera X wyróżnia się osobno, co oznacza informację szczególnie cenną, stanowiącą tajemnicę państwową najwyższego stopnia. Niech ci, którzy mają to robić na służbie, poszukają takich dokumentów, a my ograniczymy się do plików z literą C. Zgodnie z dyrektywą DoDI 5230.24 oznaczenie to przypisuje się dokumentom zawierającym opis technologii krytycznych objętych kontrolą eksportu . Tak starannie chronione informacje można znaleźć na stronach w domenie najwyższego poziomu.mil, przeznaczonej dla armii amerykańskiej.
„OŚWIADCZENIE O DYSTRYBUCJI C” inurl:navy.mil 
Bardzo wygodne jest to, że domena .mil zawiera wyłącznie witryny Departamentu Obrony USA i jego organizacji kontraktowych. Wyniki wyszukiwania z ograniczeniem domeny są wyjątkowo przejrzyste, a tytuły mówią same za siebie. Wyszukiwanie w ten sposób rosyjskich tajemnic jest praktycznie bezużyteczne: w domenach.ru i.rf panuje chaos, a nazwy wielu systemów uzbrojenia brzmią jak botaniczne (PP „Kiparis”, działa samobieżne „Akatsia”) lub wręcz bajeczne ( Regulamin „Buratino”).

Uważnie studiując dowolny dokument z witryny w domenie .mil, możesz zobaczyć inne znaczniki, aby zawęzić wyszukiwanie. Na przykład odniesienie do ograniczeń eksportowych „Sec 2751”, co jest również wygodne przy wyszukiwaniu interesujących informacji technicznych. Od czasu do czasu jest usuwany z oficjalnych stron, na których się kiedyś pojawił, więc jeśli nie możesz skorzystać z interesującego linku w wynikach wyszukiwania, skorzystaj z pamięci podręcznej Google (operatora pamięci podręcznej) lub witryny Internet Archive.
Wspinaczka w chmury
Oprócz przypadkowo odtajnionych dokumentów rządowych w pamięci podręcznej Google czasami pojawiają się łącza do plików osobistych z Dropbox i innych usług przechowywania danych, które tworzą „prywatne” łącza do publicznie publikowanych danych. Jeszcze gorzej jest z usługami alternatywnymi i domowymi. Na przykład poniższe zapytanie pozwala znaleźć dane wszystkich klientów Verizon, którzy mają zainstalowany serwer FTP i aktywnie korzystają z routera.
Allinurl:ftp://verizon.net
Takich mądrych ludzi jest obecnie ponad czterdzieści tysięcy, a wiosną 2015 roku było ich znacznie więcej. Zamiast Verizon.net możesz zastąpić nazwę dowolnego znanego dostawcy, a im jest on bardziej znany, tym większy może być haczyk. Dzięki wbudowanemu serwerowi FTP możesz przeglądać pliki znajdujące się na zewnętrznym urządzeniu magazynującym podłączonym do routera. Zwykle jest to serwer NAS do pracy zdalnej, chmura osobista lub jakiś rodzaj pobierania plików peer-to-peer. Cała zawartość takich multimediów jest indeksowana przez Google i inne wyszukiwarki, dzięki czemu dostęp do plików przechowywanych na dyskach zewnętrznych można uzyskać poprzez bezpośredni link.

Patrząc na konfiguracje
Przed powszechną migracją do chmury proste serwery FTP rządziły jako zdalny magazyn, który również miał wiele luk w zabezpieczeniach. Wiele z nich jest nadal aktualnych. Na przykład popularny program WS_FTP Professional przechowuje dane konfiguracyjne, konta użytkowników i hasła w pliku ws_ftp.ini. Łatwo je znaleźć i odczytać, ponieważ wszystkie rekordy są zapisywane w formacie tekstowym, a hasła są szyfrowane algorytmem Triple DES po minimalnym zaciemnieniu. W większości wersji wystarczy po prostu odrzucić pierwszy bajt.

Takie hasła można łatwo odszyfrować za pomocą narzędzia WS_FTP Password Deszyfrator lub bezpłatnej usługi internetowej.

Mówiąc o włamaniu na dowolną stronę internetową, zwykle mają na myśli uzyskanie hasła z logów i kopii zapasowych plików konfiguracyjnych CMS-ów lub aplikacji e-commerce. Jeśli znasz ich typową strukturę, możesz łatwo wskazać słowa kluczowe. Linie takie jak te znajdujące się w pliku ws_ftp.ini są niezwykle powszechne. Przykładowo w Drupalu i PrestaShop zawsze znajduje się identyfikator użytkownika (UID) i odpowiadające mu hasło (pwd), a wszystkie informacje przechowywane są w plikach z rozszerzeniem .inc. Można je wyszukiwać w następujący sposób:
"pwd=" "UID=" wew:inc
Ujawnianie haseł DBMS
W plikach konfiguracyjnych serwerów SQL nazwy użytkowników i adresy e-mail są przechowywane w postaci zwykłego tekstu, a zamiast haseł zapisywane są ich skróty MD5. Ściśle mówiąc, nie da się ich odszyfrować, ale można znaleźć dopasowanie wśród znanych par hash-hasło.

Nadal istnieją systemy DBMS, które nawet nie używają mieszania haseł. Pliki konfiguracyjne dowolnego z nich można po prostu przeglądać w przeglądarce.
Intext:DB_PASSWORD typ pliku:env

Wraz z pojawieniem się serwerów Windows miejsce plików konfiguracyjnych częściowo zajął rejestr. Możesz przeszukiwać jego gałęzie dokładnie w ten sam sposób, używając reg jako typu pliku. Na przykład tak:
Typ pliku:reg HKEY_CURRENT_USER "Hasło"=

Nie zapominajmy o oczywistościach
Czasami do informacji niejawnych można dotrzeć przy użyciu danych, które zostały przypadkowo otwarte i na które zwróciła uwagę Google. Idealną opcją jest znalezienie listy haseł w jakimś popularnym formacie. Tylko zdesperowani ludzie mogą przechowywać informacje o koncie w pliku tekstowym, dokumencie Worda lub arkuszu kalkulacyjnym Excel, ale zawsze jest ich wystarczająco dużo.
Typ pliku:xls inurl:hasło

Z jednej strony istnieje wiele sposobów zapobiegania takim zdarzeniom. Należy określić odpowiednie prawa dostępu w htaccess, załatać CMS, nie używać leworęcznych skryptów i załatać inne dziury. Istnieje również plik z listą wyjątków w pliku robots.txt, który zabrania wyszukiwarkom indeksowania określonych w nim plików i katalogów. Z drugiej strony, jeśli struktura pliku robots.txt na jakimś serwerze różni się od standardowej, wówczas od razu staje się jasne, co próbują na nim ukryć.

Lista katalogów i plików w dowolnej witrynie jest poprzedzona standardowym indeksem. Ponieważ dla celów serwisowych musi pojawić się w tytule, warto ograniczyć wyszukiwanie do operatora intitle. Ciekawe rzeczy znajdują się w katalogach /admin/, /personal/, /etc/, a nawet /secret/.

Bądź na bieżąco z aktualizacjami
Trafność jest tutaj niezwykle ważna: stare luki w zabezpieczeniach są zamykane bardzo powoli, ale Google i jego wyniki wyszukiwania stale się zmieniają. Istnieje nawet różnica pomiędzy filtrem „ostatniej sekundy” (&tbs=qdr:s na końcu adresu URL żądania) a filtrem „czasu rzeczywistego” (&tbs=qdr:1).
Przedział czasowy ostatniej aktualizacji pliku jest również domyślnie wskazany przez Google. Za pomocą graficznego interfejsu internetowego możesz wybrać jeden ze standardowych okresów (godzina, dzień, tydzień itp.) lub ustawić zakres dat, ale ta metoda nie nadaje się do automatyzacji.
Z wyglądu paska adresu można się tylko domyślać, w jaki sposób można ograniczyć wyświetlanie wyników za pomocą konstrukcji &tbs=qdr:. Litera y po nim wyznacza limit jednego roku (&tbs=qdr:y), m pokazuje wyniki za ostatni miesiąc, w - za tydzień, d - za ostatni dzień, h - za ostatnią godzinę, n - na minutę i s - daj mi chwilę. Najnowsze wyniki, które właśnie udostępnił Google, można znaleźć za pomocą filtra &tbs=qdr:1 .
Jeśli potrzebujesz napisać sprytny skrypt, przyda się wiedza, że zakres dat ustawia się w Google w formacie juliańskim za pomocą operatora daterange. Na przykład w ten sposób możesz znaleźć listę dokumentów PDF ze słowem poufne, pobranych w okresie od 1 stycznia do 1 lipca 2015 r.
Poufny typ pliku: pdf zakres dat: 2457024-2457205
Zakres jest podany w formacie daty juliańskiej bez uwzględnienia części ułamkowej. Ręczne tłumaczenie ich z kalendarza gregoriańskiego jest niewygodne. Łatwiej jest użyć konwertera dat.
Kierowanie i filtrowanie ponownie
Oprócz określenia w zapytaniu dodatkowych operatorów, można je przesłać bezpośrednio w treści linku. Na przykład specyfikacja filetype:pdf odpowiada konstrukcji as_filetype=pdf . Dzięki temu wygodnie jest poprosić o wyjaśnienia. Załóżmy, że wyjście wyników tylko z Republiki Hondurasu jest określone poprzez dodanie konstrukcji cr=countryHN do adresu URL wyszukiwania i tylko z miasta Bobrujsk - gcs=Bobruisk. Pełną listę znajdziesz w sekcji dla programistów.
Narzędzia Google do automatyzacji mają za zadanie ułatwiać życie, ale często powodują problemy. Na przykład miasto użytkownika jest określane na podstawie adresu IP użytkownika za pośrednictwem WHOIS. Na podstawie tych informacji Google nie tylko równoważy obciążenie pomiędzy serwerami, ale także zmienia wyniki wyszukiwania. W zależności od regionu, dla tego samego żądania na pierwszej stronie pojawią się różne wyniki, a niektóre z nich mogą być całkowicie ukryte. Dwuliterowy kod znajdujący się po dyrektywie gl=country pomoże Ci poczuć się jak kosmopolita i szukać informacji z dowolnego kraju. Na przykład kod Holandii to NL, ale Watykan i Korea Północna nie mają własnego kodu w Google.
Często wyniki wyszukiwania są zaśmiecone nawet po zastosowaniu kilku zaawansowanych filtrów. W takim przypadku łatwo jest doprecyzować żądanie, dodając do niego kilka słów wyjątków (przed każdym z nich umieszcza się znak minus). Na przykład bankowość, imiona i samouczki są często używane ze słowem Osobiste. Dlatego czystsze wyniki wyszukiwania pokaże nie podręcznikowy przykład zapytania, ale doprecyzowany:
Tytuł:"Indeks /Osobiste/" -imiona -tutorial -bankowość
Ostatni przykład
Wyrafinowany haker wyróżnia się tym, że we własnym zakresie zapewnia sobie wszystko, czego potrzebuje. Na przykład VPN jest wygodną rzeczą, ale albo kosztowną, albo tymczasową i z ograniczeniami. Zapisanie się na abonament dla siebie jest zbyt drogie. Dobrze, że są abonamenty grupowe, a przy pomocy Google łatwo jest zostać częścią grupy. Aby to zrobić, wystarczy znaleźć plik konfiguracyjny Cisco VPN, który ma dość niestandardowe rozszerzenie PCF i rozpoznawalną ścieżkę: Program Files\Cisco Systems\VPN Client\Profiles. Jedna prośba i dołączysz na przykład do przyjaznego zespołu Uniwersytetu w Bonn.
Typ pliku:pcf VPN LUB grupa

INFORMACJE
Google znajduje pliki konfiguracyjne haseł, ale wiele z nich jest zaszyfrowanych lub zastąpionych skrótami. Jeśli zobaczysz ciągi o stałej długości, natychmiast poszukaj usługi deszyfrowania.Hasła są przechowywane w postaci zaszyfrowanej, ale Maurice Massard napisał już program do ich odszyfrowania i udostępnia go bezpłatnie za pośrednictwem thecampusgeeks.com.
Google przeprowadza setki różnych rodzajów ataków i testów penetracyjnych. Istnieje wiele opcji wpływających na popularne programy, główne formaty baz danych, liczne luki w zabezpieczeniach PHP, chmur i tak dalej. Dokładna wiedza, czego szukasz, znacznie ułatwi znalezienie potrzebnych informacji (zwłaszcza informacji, których nie zamierzałeś upubliczniać). Shodan nie jest jedynym, który karmi się ciekawymi pomysłami, ale każdą bazą danych zindeksowanych zasobów sieciowych!
To staje się zabawne za każdym razem, gdy ludzie zaczynają mówić o prywatnych głupkach.
Zacznijmy od zdefiniowania, czym jest kretyn, a czym prywatny:
DORK (DORKA)- jest to maska, czyli inaczej żądanie skierowane do wyszukiwarki, w odpowiedzi na które system wygeneruje listę stron serwisu, których adresy zawierają ten sam DORK.
Prywatny- informacje, do których dostęp ma tylko jedna osoba lub niewielka grupa osób pracujących nad jednym projektem.
Spójrzmy teraz na wyrażenie „ Prywatny seks
".
Jeśli wyślemy zapytanie o znalezienie stron dla danej domeny i da nam to jakiś wynik, to każdy może to zrobić, a zatem podane informacje nie są prywatne.
I trochę o sprzedawcach gier/pieniędzy/sklepów.
Wiele osób lubi robić tego typu dorki:
Steam.php?q= bitcoin.php?id= Minecraft.php?id=
Wyobraźmy sobie, że nic nie rozumiemy o dorkach i spróbujmy zobaczyć, ile linków podaje nam Google:
Prawdopodobnie od razu pomyślałeś o takich myślach: „Chrenowicz, gówno wiesz, spójrz, ile jest linków, ludzie praktycznie sprzedają pieniądze!”
Ale powiem Ci, że nie, bo teraz zobaczmy, jakie linki da nam taka prośba:

Myślę, że rozumiesz, o co chodzi, teraz użyjmy operatora Google adres: dokładne wyszukiwanie i zobaczmy, co wyjdzie:

Tak, liczba gwałtownie spadła, potem to samo. A jeśli weźmiemy pod uwagę, że będą zduplikowane domeny + linki planu ***.info/vaernamo-nyheter/dennis-steam.php, to ostatecznie wyjdzie nam 5-10 sztuk.
Jak myślisz, ile osób doda takie linki do swojej witryny?
Aby zobaczyć linki, musisz się zarejestrować.
„itd., tak, oczywiście, tylko kilka.
Co oznacza pisanie kretynów w stylu steam.php?id= nie ma sensu, więc pytanie, jakie dorki ugotować?
I wszystko jest dość proste, musimy zebrać jak najwięcej linków na naszych drzwiach. Najwięcej linków będzie pochodzić z najbardziej prymitywnego linku formularza indeks.php?id=

Ups, aż 538 milionów, niezły wynik, prawda?
Dodajmy więcej adres:

Cóż, połowa z nich zniknęła, ale teraz prawie wszystkie linki będą miały indeks.php?id=
Z powyższego możemy wyciągnąć wniosek: potrzebujemy najczęściej używanych katalogów, to z nich nasze wyniki będą najwyższe.
Myślę, że wiele osób myślało w stylu: "No i co dalej? Potrzebujemy witryn tematycznych, a nie wszelkiego rodzaju witryn dla miłośników szczeniąt!" Cóż, oczywiście, ale aby przejść do tematów witryn, będziemy musieli zapoznać się z operatorami Google, zaczynajmy. Nie będziemy analizować wszystkich operatorów, a jedynie te, które pomogą nam w parsowaniu strony.
Jakimi operatorami jesteśmy zainteresowani:
adres: Wyświetla witryny zawierające określone słowo w adresie strony.
Przykład:
Potrzebujemy witryn, których adres strony zawiera to słowo wózek. Utwórzmy żądanie typu inurl:koszyk i wyświetli nam wszystkie linki, których adres zawiera słowo koszyk. Te. Korzystając z tego żądania, osiągnęliśmy bardziej rygorystyczne przestrzeganie naszych warunków i eliminację linków, które nam nie odpowiadają.
w tekście: Strony są wybierane na podstawie zawartości strony.
Przykład:
Załóżmy, że potrzebujemy stron, na których zapisane są słowa bitcoin. Utwórzmy żądanie typu tekst:bitcoin, Teraz poda nam linki, w których w tekście użyto słowa bitcoin.
tytuł: Wyświetlają się strony, które w tytule mają słowa określone w zapytaniu.Myślę, że już wiesz jak pisać zapytania, więc nie będę podawać przykładów.
allinanchor: operator wyświetla strony, które w swoim opisie mają interesujące nas słowa.
powiązany: być może jeden z ważnych operatorów udostępniających witryny o podobnej treści.
Przykład:
powiązane:exmo.com - poda nam wymiany, spróbuj sprawdzić to sam.
Cóż, być może wszyscy główni operatorzy, których potrzebujemy.
Przejdźmy teraz do budowy dróg za pomocą tych operatorów.
Przed każdymi drzwiami umieścimy inurl:
Inurl:cart?id= inurl:index?id= inurl:catalog?id=
Użyjmy także intekstu: powiedzmy, że szukamy zabawek, co oznacza, że potrzebujemy słów takich jak dota2, portal, CSGO...
Intext:dota2 intext:portal intext:csgo
Jeśli potrzebujemy frazy, to allinurl:
Allinurl:GTA SAMP...
Teraz sklejmy to wszystko i otrzymamy taki wygląd:
Inurl:cart?id= intext:dota2 inurl:cart?id= intext:portal inurl:cart?id= intext:csgo inurl:cart?id= allinurl:GTA SAMP inurl:index?id= intext:dota2 inurl:index? id= intext:portal inurl:index?id= intext:csgo inurl:index?id= allinurl:GTA SAMP inurl:catalog?id= intext:dota2 inurl:catalog?id= intext:portal inurl:catalog?id= intext: csgo inurl:catalog?id= allinurl:GTA SAMP
W rezultacie otrzymaliśmy drzwi do gier z węższym i dokładniejszym wyszukiwaniem.
Więc użyj mózgu i poeksperymentuj trochę z operatorami wyszukiwania i słowami kluczowymi, nie musisz się wypaczać i pisać głupstw w stylu hochymnogoigr.php?id=
Dziękuję wszystkim, mam nadzieję, że wyciągnęliście przynajmniej coś przydatnego z tego artykułu.
Wyszukiwarka Google (www.google.com) udostępnia wiele opcji wyszukiwania. Wszystkie te funkcje są nieocenionym narzędziem wyszukiwania dla nowicjusza w Internecie i jednocześnie jeszcze potężniejszą bronią inwazji i zniszczenia w rękach ludzi o złych intencjach, w tym nie tylko hakerów, ale także przestępców niekomputerowych i nawet terroryści.
(9475 wyświetleń w 1 tydzień)
Denis Barankow
denisNOSPAMixi.ru
Uwaga:Ten artykuł nie jest przewodnikiem po działaniu. Ten artykuł został napisany z myślą o Was, administratorach serwerów WWW, abyście pozbyli się fałszywego poczucia bezpieczeństwa, a w końcu zrozumieli podstępność tej metody pozyskiwania informacji i podjęli się zadania ochrony swojej witryny.
Wstęp
Na przykład znalazłem 1670 stron w 0,14 sekundy!
2. Wprowadźmy inną linię, na przykład:
inurl:"auth_user_file.txt"trochę mniej, ale to już wystarczy do bezpłatnego pobrania i odgadnięcia hasła (przy użyciu tego samego Johna Rozpruwacza). Poniżej podam jeszcze kilka przykładów.
Trzeba więc zdać sobie sprawę, że wyszukiwarka Google odwiedziła większość stron internetowych i zapisała w pamięci podręcznej zawarte na nich informacje. Te informacje zapisane w pamięci podręcznej umożliwiają uzyskanie informacji o witrynie i zawartości witryny bez bezpośredniego łączenia się z witryną, jedynie poprzez zagłębienie się w informacje przechowywane w Google. Co więcej, jeśli informacje na stronie nie są już dostępne, informacje w pamięci podręcznej mogą nadal zostać zachowane. Aby skorzystać z tej metody, wystarczy znać kilka słów kluczowych Google. Ta technika nazywa się hakowaniem Google.
Informacje o Google Hacking po raz pierwszy pojawiły się na liście mailingowej Bugtruck 3 lata temu. W 2001 roku temat ten podjął francuski student. Oto link do tego listu http://www.cotse.com/mailing-lists/bugtraq/2001/Nov/0129.html. Podaje pierwsze przykłady takich zapytań:
1) Indeks /admin
2) Indeks /hasło
3) Indeks /mail
4) Indeks / +banques +filetype:xls (dla Francji...)
5) Indeks / +hasło
6) Indeks /hasło.txt
Temat ten zrobił furorę w anglojęzycznej części Internetu całkiem niedawno: po artykule Johnny'ego Longa opublikowanym 7 maja 2004 roku. Aby uzyskać pełniejsze informacje na temat hakowania w Google, radzę odwiedzić witrynę tego autora http://johnny.ihackstuff.com. W tym artykule chcę tylko przedstawić Ci aktualne informacje.
Kto może z tego skorzystać:
- Dziennikarze, szpiedzy i wszyscy, którzy lubią wtykać nos w cudze sprawy, mogą to wykorzystać do poszukiwania obciążających dowodów.
- Hakerzy poszukujący odpowiednich celów do włamań.
Jak działa Google.
Aby kontynuować rozmowę, przypomnę kilka słów kluczowych używanych w zapytaniach Google.
Wyszukaj za pomocą znaku +
Google wyklucza z wyszukiwania słowa, które uważa za nieistotne. Na przykład słowa pytające, przyimki i rodzajniki w języku angielskim: na przykład są, z, gdzie. Wydaje się, że w języku rosyjskim Google uważa wszystkie słowa za ważne. Jeśli słowo zostanie wykluczone z wyszukiwania, Google o tym pisze. Aby Google zaczął wyszukiwać strony zawierające te słowa, należy przed słowem dodać znak + bez spacji. Na przykład:
as + bazy
Szukaj po znaku –
Jeśli Google znajdzie dużą liczbę stron, z których musi wykluczyć strony o określonej tematyce, możesz zmusić Google do wyszukiwania tylko stron, które nie zawierają określonych słów. Aby to zrobić, musisz wskazać te słowa, umieszczając znak przed każdym słowem - bez spacji przed słowem. Na przykład:
wędkarstwo - wódka
Wyszukaj za pomocą ~
Możesz wyszukać nie tylko określone słowo, ale także jego synonimy. Aby to zrobić, poprzedź słowo symbolem ~.
Znalezienie dokładnej frazy za pomocą podwójnych cudzysłowów
Google wyszukuje na każdej stronie wszystkie wystąpienia słów, które wpisałeś w ciągu zapytania i nie zwraca uwagi na względną pozycję słów, byle wszystkie określone słowa znalazły się na stronie w tym samym czasie (jest to akcja domyślna). Aby znaleźć dokładne wyrażenie, należy je umieścić w cudzysłowie. Na przykład:
„podpórka”
Aby mieć chociaż jedno z podanych słów, należy jawnie określić operację logiczną: OR. Na przykład:
bezpieczeństwo książki LUB ochrona
Ponadto możesz użyć znaku * w pasku wyszukiwania, aby wskazać dowolne słowo i. reprezentować dowolną postać.
Wyszukiwanie słów za pomocą dodatkowych operatorów
Istnieją operatory wyszukiwania, które są określone w ciągu wyszukiwania w formacie:
operator:search_term
Spacje obok dwukropka nie są potrzebne. Jeśli wstawisz spację po dwukropku, pojawi się komunikat o błędzie, a przed nim Google użyje ich jako normalnego ciągu wyszukiwania.
Istnieją grupy dodatkowych operatorów wyszukiwania: języki – wskaż, w jakim języku chcesz zobaczyć wynik, data – ogranicz wyniki do ostatnich trzech, sześciu lub 12 miesięcy, wystąpienia – wskaż, gdzie w dokumencie chcesz szukać linia: wszędzie, w tytule, w adresie URL, w domenach - wyszukaj w określonej witrynie lub odwrotnie, wyklucz ją z wyszukiwania; bezpieczne wyszukiwanie - blokuje witryny zawierające określony typ informacji i usuwa je ze stron wyników wyszukiwania.
Jednak niektórzy operatorzy nie wymagają dodatkowego parametru, np. żądanie „ pamięć podręczna: www.google.com„ można nazwać pełnoprawnym ciągiem wyszukiwania, a wręcz przeciwnie, niektóre słowa kluczowe wymagają wyszukiwanego słowa, na przykład „ witryna: www.google.com pomoc". W świetle naszego tematu przyjrzyjmy się następującym operatorom:
Operator |
Opis |
Wymaga dodatkowego parametru? |
szukaj tylko w witrynie określonej w search_term |
||
szukaj tylko w dokumentach z typem search_term |
||
znajdź strony zawierające wyszukiwane hasło w tytule |
||
znajdź strony zawierające w tytule wszystkie słowa wyszukiwanego hasła |
||
znajdź strony zawierające w adresie słowo search_term |
||
znajdź strony zawierające w swoim adresie wszystkie słowa wyszukiwanych terminów |
Operator strona: ogranicza wyszukiwanie tylko do określonej witryny i możesz podać nie tylko nazwę domeny, ale także adres IP. Na przykład wpisz:
Operator Typ pliku: Ogranicza wyszukiwanie do określonego typu pliku. Na przykład:
Na dzień publikacji artykułu Google może wyszukiwać pliki w 13 różnych formatach:
- Format dokumentu Adobe Portable (pdf)
- Adobe PostScript (ps)
- Lotos 1-2-3 (tydzień 1, tydzień 2, tydzień 3, tydzień 4, tydzień 5, wki, tydzień, wku)
- Lotus WordPro (lwp)
- MacWrite (mw)
- Microsoft Excel (xls)
- Microsoft PowerPoint (ppt)
- Microsoft Word (doc)
- Microsoft Works (wks, wps, wdb)
- Microsoft Write (wri)
- Format tekstu sformatowanego (rtf)
- Shockwave Flash (swf)
- Tekst (ans, txt)
Operator połączyć: pokazuje wszystkie strony, które wskazują na określoną stronę.
Prawdopodobnie zawsze interesujące jest sprawdzenie, ile miejsc w Internecie wie o Tobie. Spróbujmy:
Operator Pamięć podręczna: Pokazuje wersję witryny w pamięci podręcznej Google, tak jak wyglądała, gdy Google odwiedził tę stronę po raz ostatni. Weźmy dowolną często zmieniającą się witrynę i spójrzmy:
Operator tytuł: wyszukuje określone słowo w tytule strony. Operator tytuł całego: jest rozszerzeniem - wyszukuje wszystkie określone kilka słów w tytule strony. Porównywać:
tytuł:Lot na Marsa
intitle:lot intitle:na intitle:mars
allintitle:lot na Marsa
Operator adres: zmusza Google do wyświetlenia wszystkich stron zawierających określony ciąg w adresie URL. operator allinurl: wyszukuje wszystkie słowa w adresie URL. Na przykład:
allinurl:acid acid_stat_alerts.php
To polecenie jest szczególnie przydatne dla tych, którzy nie mają SNORT - przynajmniej mogą zobaczyć, jak to działa na prawdziwym systemie.
Metody hakowania przy użyciu Google
Odkryliśmy więc, że stosując kombinację powyższych operatorów i słów kluczowych, każdy może zebrać niezbędne informacje i wyszukać luki. Techniki te są często nazywane hakowaniem Google.
Mapa witryny
Za pomocą operatora site: możesz wyświetlić listę wszystkich linków znalezionych przez Google w witrynie. Zazwyczaj strony tworzone dynamicznie przez skrypty nie są indeksowane przy użyciu parametrów, więc niektóre witryny korzystają z filtrów ISAPI, dzięki czemu linki nie są w formie /article.asp?num=10&dst=5 i z ukośnikami /article/abc/num/10/dst/5. Dzieje się tak, aby witryna była ogólnie indeksowana przez wyszukiwarki.
Spróbujmy:
strona: www.whitehouse.gov Whitehouse
Google uważa, że każda strona w witrynie zawiera słowo whitehouse. Tego używamy do uzyskania wszystkich stron.
Istnieje również wersja uproszczona:
strona:whitehouse.gov
A najlepsze jest to, że towarzysze z whitehouse.gov nawet nie wiedzieli, że sprawdziliśmy strukturę ich witryny, a nawet sprawdziliśmy strony z pamięci podręcznej pobrane przez Google. Można to wykorzystać do badania struktury witryn i przeglądania treści, pozostając na razie niewykrytym.
Wyświetl listę plików w katalogach
Serwery WWW mogą wyświetlać listy katalogów serwerów zamiast zwykłych stron HTML. Zwykle robi się to, aby mieć pewność, że użytkownicy wybiorą i pobiorą określone pliki. Jednak w wielu przypadkach administratorzy nie mają zamiaru pokazywać zawartości katalogu. Dzieje się tak z powodu nieprawidłowej konfiguracji serwera lub braku strony głównej w katalogu. Dzięki temu haker ma szansę znaleźć w katalogu coś interesującego i wykorzystać to do własnych celów. Aby znaleźć wszystkie takie strony, wystarczy zauważyć, że wszystkie zawierają słowa: indeks. Ponieważ jednak indeks słów zawiera nie tylko takie strony, musimy doprecyzować zapytanie i wziąć pod uwagę słowa kluczowe znajdujące się na samej stronie, więc zapytania typu:
intitle:index.of katalogu nadrzędnego
intitle:index.of rozmiar nazwy
Ponieważ większość wpisów w katalogach jest celowych, znalezienie zagubionych wpisów za pierwszym razem może być trudne. Ale przynajmniej możesz już używać list do określenia wersji serwera WWW, jak opisano poniżej.
Uzyskanie wersji serwera WWW.
Znajomość wersji serwera WWW jest zawsze przydatna przed rozpoczęciem ataku hakerskiego. Ponownie, dzięki Google, możesz uzyskać te informacje bez łączenia się z serwerem. Jeśli przyjrzysz się uważnie liście katalogów, zobaczysz, że wyświetlana jest tam nazwa serwera WWW i jego wersja.
Apache 1.3.29 — serwer ProXad pod adresem trf296.free.fr, port 80
Doświadczony administrator może zmienić te informacje, ale z reguły jest to prawda. Zatem, aby uzyskać taką informację wystarczy wysłać zapytanie:
intitle:index.of serwer.at
Aby uzyskać informacje dla konkretnego serwera, wyjaśniamy żądanie:
intitle:index.of server.at site:ibm.com
Lub odwrotnie, szukamy serwerów, na których działa konkretna wersja serwera:
intitle:index.of Apache/2.0.40 Serwer pod adresem
Haker może wykorzystać tę technikę do znalezienia ofiary. Jeśli na przykład ma exploit dla określonej wersji serwera WWW, może go znaleźć i wypróbować istniejący exploit.
Wersję serwerową można także uzyskać przeglądając strony instalowane domyślnie podczas instalacji najnowszej wersji serwera WWW. Na przykład, aby wyświetlić stronę testową Apache 1.2.6, po prostu wpisz
intitle:Test.Page.for.Apache.udało się!
Co więcej, niektóre systemy operacyjne natychmiast instalują i uruchamiają serwer WWW podczas instalacji. Jednak niektórzy użytkownicy nawet nie są tego świadomi. Naturalnie, jeśli zauważysz, że ktoś nie usunął strony domyślnej, logiczne jest założenie, że komputer nie został w ogóle poddany żadnym dostosowaniom i prawdopodobnie jest podatny na atak.
Spróbuj wyszukać strony IIS 5.0
allintitle:Witamy w usługach internetowych systemu Windows 2000
W przypadku IIS można określić nie tylko wersję serwera, ale także wersję systemu Windows i Service Pack.
Innym sposobem ustalenia wersji serwera WWW jest wyszukanie podręczników (stron pomocy) i przykładów, które mogą być domyślnie zainstalowane w serwisie. Hakerzy znaleźli sporo sposobów wykorzystania tych komponentów w celu uzyskania uprzywilejowanego dostępu do witryny. Dlatego należy usunąć te komponenty na miejscu produkcji. Nie wspominając już o tym, że obecność tych komponentów może zostać wykorzystana do uzyskania informacji o typie serwera i jego wersji. Na przykład znajdźmy podręcznik Apache:
inurl: ręczne moduły dyrektyw Apache
Używanie Google jako skanera CGI.
Skaner CGI lub skaner WEB to narzędzie służące do wyszukiwania podatnych na ataki skryptów i programów na serwerze ofiary. Te narzędzia muszą wiedzieć, czego szukać, w tym celu mają całą listę wrażliwych plików, na przykład:
/cgi-bin/cgiemail/uargg.txt
/random_banner/index.cgi
/random_banner/index.cgi
/cgi-bin/mailview.cgi
/cgi-bin/maillist.cgi
/cgi-bin/userreg.cgi
/iissamples/ISSamples/SQLQHit.asp
/SiteServer/admin/findvserver.asp
/scripts/cphost.dll
/cgi-bin/finger.cgi
Każdy z tych plików możemy znaleźć za pomocą Google, dodatkowo wykorzystując w wyszukiwarce słowa indeks lub inurl przy nazwie pliku: możemy znaleźć strony z podatnymi na ataki skryptami, np.:
allinurl:/random_banner/index.cgi
Wykorzystując dodatkową wiedzę, haker może wykorzystać lukę w skrypcie i wykorzystać tę lukę, aby wymusić na skrypcie wyemitowanie dowolnego pliku przechowywanego na serwerze. Na przykład plik haseł.
Jak chronić się przed hakerami Google.
1. Nie zamieszczaj ważnych danych na serwerze WWW.
Nawet jeśli umieściłeś dane tymczasowo, możesz o nich zapomnieć lub ktoś będzie miał czas na ich odnalezienie i zabranie, zanim je usuniesz. Nie rób tego. Istnieje wiele innych sposobów przesyłania danych, które chronią je przed kradzieżą.
2. Sprawdź swoją witrynę.
Skorzystaj z opisanych metod, aby zbadać swoją witrynę. Sprawdzaj okresowo swoją witrynę pod kątem nowych metod pojawiających się na stronie http://johnny.ihackstuff.com. Pamiętaj, że jeśli chcesz zautomatyzować swoje działania, musisz uzyskać specjalne pozwolenie od Google. Jeśli przeczytasz uważnie http://www.google.com/terms_of_service.html, zobaczysz następujący komunikat: Nie możesz wysyłać żadnego rodzaju automatycznych zapytań do systemu Google bez uprzedniej wyraźnej zgody Google.
3. Być może nie będziesz potrzebować Google do indeksowania Twojej witryny lub jej części.
Google umożliwia usunięcie linku do Twojej witryny lub jej części z bazy danych, a także usunięcie stron z pamięci podręcznej. Dodatkowo możesz zabronić wyszukiwania obrazów w Twojej witrynie, zabronić pokazywania krótkich fragmentów stron w wynikach wyszukiwania.Wszystkie możliwości usunięcia witryny są opisane na stronie http://www.google.com/remove.html. Aby to zrobić, musisz potwierdzić, że naprawdę jesteś właścicielem tej witryny lub wstawić tagi na stronę lub
4. Użyj pliku robots.txt
Wiadomo, że wyszukiwarki przeglądają plik robots.txt znajdujący się w katalogu głównym witryny i nie indeksują tych części, które są oznaczone słowem Uniemożliwić. Możesz użyć tej opcji, aby zapobiec indeksowaniu części witryny. Na przykład, aby zapobiec zaindeksowaniu całej witryny, utwórz plik robots.txt zawierający dwie linie:
Agent użytkownika: *
Uniemożliwić: /
Co jeszcze się stanie
Aby życie nie wydawało Ci się miodkiem, na koniec powiem, że istnieją strony monitorujące osoby, które korzystając z metod opisanych powyżej, szukają dziur w skryptach i serwerach WWW. Przykładem takiej strony jest
Aplikacja.
Trochę słodko. Wypróbuj niektóre z poniższych rozwiązań dla siebie:
1. #mysql dump typ pliku:sql - wyszukaj zrzuty bazy danych MySQL
2. Raport podsumowujący luki w zabezpieczeniach hosta — pokaże Ci, jakie luki w zabezpieczeniach znalazły inne osoby
3. phpMyAdmin działający na inurl:main.php - wymusi to zamknięcie kontroli poprzez panel phpmyadmin
4. nie do rozpowszechniania w tajemnicy
5. Szczegóły żądania Zmienne serwera drzewa sterującego
6. Uruchomienie w trybie dziecka
7. Ten raport został wygenerowany przez WebLog
8. intitle:index.of cgiirc.config
9. filetype:conf inurl:firewall -intitle:cvs – może ktoś potrzebuje plików konfiguracyjnych firewalla? :)
10. tytuł:indeks.finansów.xls – hmm....
11. intitle:Indeks czatów dbconvert.exe – logi czatów icq
12.intext:Analiza ruchu Tobiasa Oetikera
13. intitle:Statystyki użytkowania wygenerowane przez Webalizer
14. intitle:statystyka zaawansowanych statystyk internetowych
15. intitle:index.of ws_ftp.ini – konfiguracja ws ftp
16. inurl:ipsec.secrets przechowuje wspólne sekrety - tajny klucz - dobre znalezisko
17. inurl:main.php Witamy w phpMyAdmin
18. inurl:server-info Informacje o serwerze Apache
19. site:oceny administratora edukacji
20. ORA-00921: nieoczekiwany koniec polecenia SQL – pobieranie ścieżek
21. intitle:index.of trillian.ini
22. intitle:Indeks pwd.db
23.intitle:indeks.osób.lst
24. intitle:index.of master.passwd
25.inurl:passlist.txt
26. intitle:Indeks .mysql_history
27. intitle:index of intext:globals.inc
28. intitle:index.of administrators.pwd
29. intitle:Index.of itp. cień
30.intitle:index.ofsecring.pgp
31. inurl:config.php nazwa dbu dbpass
32. inurl:wykonaj typ pliku:ini
Centrum szkoleniowe „Informzashita” http://www.itsecurity.ru - wiodący wyspecjalizowany ośrodek w zakresie szkoleń z zakresu bezpieczeństwa informacji (Licencja Moskiewskiego Komitetu Edukacji nr 015470, akredytacja państwowa nr 004251). Jedyne autoryzowane centrum szkoleniowe z zakresu Internet Security Systems i Clearswift w Rosji i krajach WNP. Autoryzowane centrum szkoleniowe Microsoft (specjalizacja Bezpieczeństwo). Programy szkoleniowe są koordynowane z Państwową Komisją Techniczną Rosji, FSB (FAPSI). Certyfikaty szkoleń i dokumenty państwowe dotyczące szkoleń zaawansowanych.
SoftKey to wyjątkowa usługa dla kupujących, programistów, dealerów i partnerów stowarzyszonych. Ponadto jest to jeden z najlepszych internetowych sklepów z oprogramowaniem w Rosji, na Ukrainie, w Kazachstanie, który oferuje klientom szeroką gamę produktów, wiele metod płatności, szybką (często natychmiastową) realizację zamówienia, śledzenie procesu zamówienia w sekcji osobistej, różne rabaty od sklepu i producentów BY.
Każde poszukiwanie luk w zasobach sieciowych rozpoczyna się od rozpoznania i zebrania informacji.
Inteligencja może być aktywna – brutalna siła plików i katalogów witryny, uruchamianie skanerów podatności, ręczne przeglądanie witryny lub pasywna – wyszukiwanie informacji w różnych wyszukiwarkach. Czasami zdarza się, że luka zostaje ujawniona jeszcze przed otwarciem pierwszej strony witryny.
Jak to jest możliwe?
Roboty wyszukujące, nieustannie wędrujące po Internecie, oprócz informacji przydatnych przeciętnemu użytkownikowi, często rejestrują rzeczy, które mogą zostać wykorzystane przez atakujących do ataku na zasób sieciowy. Na przykład błędy skryptów i pliki z poufnymi informacjami (od plików konfiguracyjnych i dzienników po pliki z danymi uwierzytelniającymi i kopiami zapasowymi baz danych).
Z punktu widzenia robota wyszukującego komunikat o błędzie dotyczący wykonania zapytania sql ma postać zwykłego tekstu, nierozerwalnie związanego np. z opisem produktów na stronie. Jeśli nagle robot wyszukiwania natknie się na plik z rozszerzeniem .sql, który z jakiegoś powodu trafi do folderu roboczego witryny, wówczas zostanie on odebrany jako część zawartości witryny i również zostanie zaindeksowany (w tym ewentualnie hasła w nim określone).
Takie informacje można znaleźć, znając mocne, często unikalne słowa kluczowe, które pomagają oddzielić „strony podatne” od stron, które nie zawierają luk.
Ogromna baza danych specjalnych zapytań wykorzystujących słowa kluczowe (tzw. dorks) istnieje na exploit-db.com i jest znana jako baza danych Google Hack.
Dlaczego Google?
Dorks są kierowane głównie do Google z dwóch powodów:
− najbardziej elastyczna składnia słów kluczowych (pokazana w tabeli 1) i znaków specjalnych (pokazana w tabeli 2);
− indeks Google jest w dalszym ciągu pełniejszy niż indeks innych wyszukiwarek;
Tabela 1 – Główne słowa kluczowe Google
| Słowo kluczowe |
Oznaczający |
Przykład |
| strona |
Szukaj tylko w określonej witrynie. Bierze pod uwagę tylko adres URL |
site:somesite.ru - znajdzie wszystkie strony w danej domenie i subdomenach |
| inurl |
Szukaj według słów obecnych w uri. W odróżnieniu od kl. słowa „site”, wyszukuje dopasowania po nazwie witryny |
inurl:news - znajduje wszystkie strony, na których dane słowo pojawia się w uri |
| w tekście |
Szukaj w treści strony |
intext:”korki” - całkowicie podobne do zwykłego zapytania o „korki” |
| tytuł |
Wyszukaj w tytule strony. Tekst pomiędzy tagami |